Push and Pull data - Pros and Cons and When to Use Each Approach
When designing data flows, choosing between pushing (sending data proactively) and pulling (retrieving data on demand) depends on factors like efficiency, latency, scalability and control.
Pushing Data:
The source system sends data automatically to the destination as they occur.
Pros of Pushing Data:
Lower Latency: Updates are delivered in real-time or near real-time.
Efficiency for High-Frequency data: Reduces the need for repeated requests when data updates frequently.
Less Client-side Processing: The destinatiuon system doesn't need to monitor or poll for changes.
Reduces Server Load (for clients). Eliminates unnecessary requests when no new data is available.
Cons of Pushing Data:
Potential Overload: if too much data is pushed once, the receiver may struggle to process it efficiently.
More Complex Error Handling: if the destination is down, data might be lost without a proper retry mechanism.
Requires Efficient Event Handling: The destination must be able to handle incoming data bursts.
Examples of Push Systems:
webhooks:
Publish-subscribe models (MQTT, Kafka)
Push notifications on mobile apps.
Pulling Data:
Definition: The Definition system requests data from the source at set intervals or on demand.
Pros of Pulling Data:
Better Control: The destination can control when and how often data is retrieved.
Avoid Data Overloaded: Only fetches what is needed, reducing unnecessary data transfers.
More Resilient to Failure: If the source is down, the destination can retry later.
Easier to implement: Simple HTTP or API calls can fetch data without requiring event-driven infrastructure.
Cons of Pulling Data:
Higher Latency: Data may be outdated between polling intervals.
Inefficinency & resource Usage: Polling too frequently wastes resources; polling too infrequently delays updates.
Increased Server Load (for sources) If many clients pull frequently, it strains the source system.
Example of Pull Systems:
REST API calls
Database queries
Web scraping
When to Use Each Approach
- Use push for real-time notifications, messaging apps, live sports scores, and stock trading platforms.
- Use pull for APIs, periodic data fetching, reports, and situations where data changes infrequently.
- Hybrid approaches (e.g., long polling, WebSockets, or event-driven architectures) can be used for a balance between efficiency and timeliness.
Choosing Between Push and Pull
When to Choose Each Approach
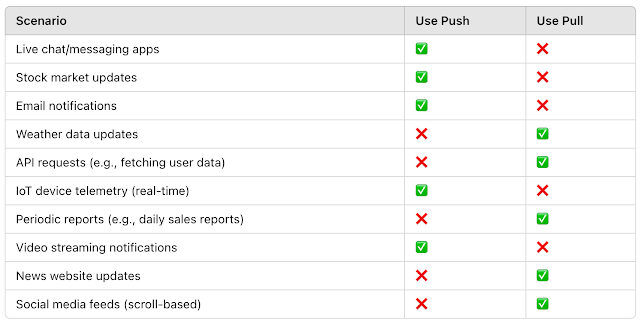


1. Frequency of Data Changes
- Frequent updates needed? → Use Push
- Best for real-time data (e.g., messaging apps, stock prices, live scores).
- Infrequent or periodic updates? → Use Pull
- Ideal for APIs, reports, and cases where data changes less often.
2. Client and Server Workload
- Push: Increases server workload since it actively sends data.
- Pull: Increases client workload since it must request data repeatedly.
- Hybrid Approach: If you want to reduce unnecessary data transfers but still need near-real-time updates, use long polling or WebSockets.
3. Network Efficiency & Bandwidth
- Push: Efficient when updates are unpredictable but frequent (reduces unnecessary requests).
- Pull: Better when updates are predictable and don’t require instant response (e.g., daily reports).
4. Scalability
- Push: Harder to scale due to the need to manage persistent connections (e.g., WebSockets).
- Pull: Easier to scale, as each request is independent.
5. Data Importance & Consistency
- Push: Ensures the latest data is always received instantly (critical for live systems).
- Pull: May lead to outdated information if polling intervals are too long.


Comments
Post a Comment